Install Local AIs
To use local AI with Shinkai you will need to install local AI models using Ollama or our simple UI.
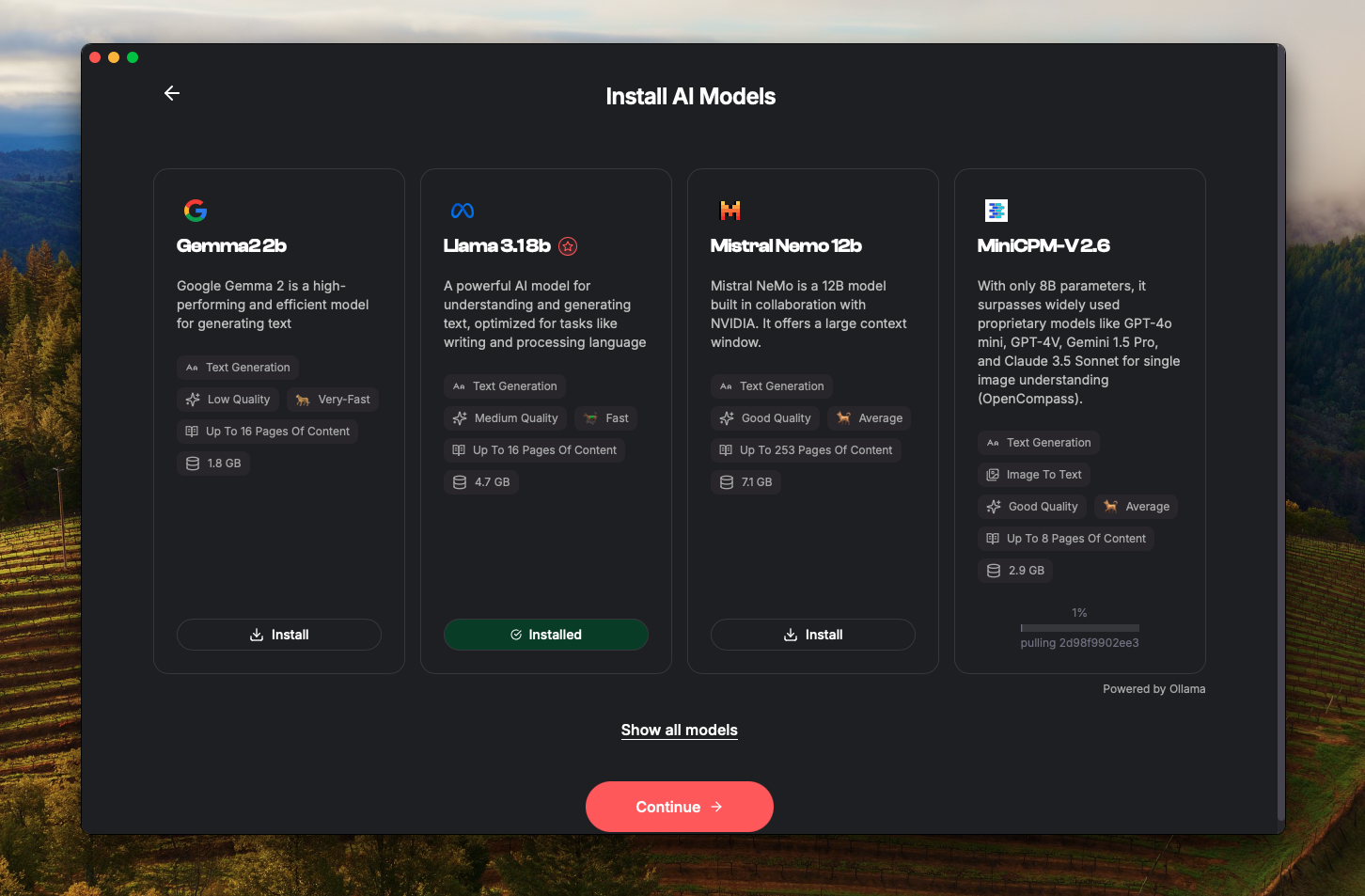
After initializing your app you will be prompted to install recommended models according to your decice specs. You can see the full list of models available by clicking 'Show all models.'
🤖AI model guideline according to your RAM
As a general rule, here is a brief guideline for model installation according to your machine specs:
8GB RAM ➡ choose 7B models or smaller. e.g., Gemma2 2b, Codegemma, Falcon, etc.
16GB RAM ➡ choose 7B, 13B models or smaller. e.g., Llama 3.1 8b, Mistral Nemo 12b, Nexusraven, etc.
32GB RAM ➡ choose 7B, 13B, 15B, 30B models or smaller. e.g., Codestral, etc.
64GB RAM ➡ choose 7B, 13B, 15B, 30B models or smaller. You might be able to go higher than that. e.g., Alfred, etc.
96GB RAM+ ➡ any model size should work for you. 🦾
💻Which AI model should I install?
As a general rule:
👟 For lightweight, fast AI needs (short conversations, basic text generation): Go with Gemma2 2b or LLaVA Phi 3.
⚖️ For balance between complexity and speed: Llama 3.1 8b is the best choice.
🧠 For handling large documents and complex reasoning: Opt for Mistral Nemo 12b, but keep in mind it will require more resources and be slower.
Ultimately, your choice depends on the type of content, performance requirements, and hardware limitations you have in your setup.
📖Understanding the 'b' in model names
The "b" in model names refers to the number of parameters in the model, measured in billions. Parameters are the variables the model uses to make predictions, learn language patterns, and generate outputs.
👀 The more parameters a model has, the more complex patterns it can learn, but this also means:
- Increased resource consumption (memory, disk space, computational power)
- Longer inference time (slower responses, unless optimized)
👇 Here’s a general guideline for understanding parameter sizes:
2b - 8b models are smaller, faster, and can handle simpler tasks. They’re more lightweight and good for smaller, real-time tasks.
10b - 70b models are larger, slower, and better for complex, nuanced tasks. They have better performance on language understanding and generation, but are resource-intensive.
💻 You have to keep in mind your own machine's specs when selecting a model.
Learn more about AI Models here